October 10, 2000: Willamette news and surprises from the Microprocessor Forum
October 10, 2000: Willamette news and surprises from the Microprocessor Forum
|
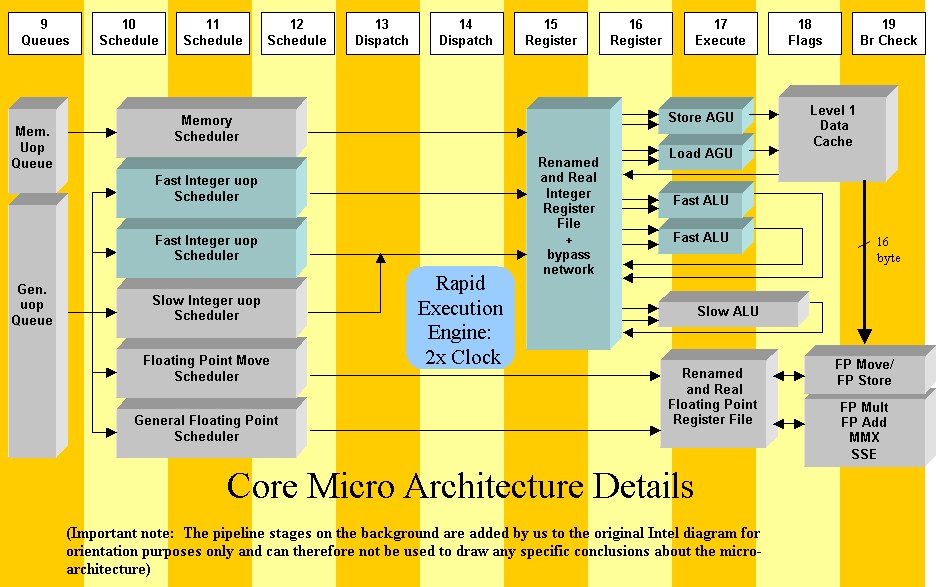
The biggest surprise during today's speech of Intels Michael Upton at the Microprocessor Forum in the Fairmount hotel in San Jose is without a doubt the disclosure that not only the Integer ALU but also several other units run at double the processor frequency. Starting with the two schedulers for the ALU's. Each double pumped ALU appears to have it's own scheduler. The entire integer register file which contains the renamed and real registers runs at the double frequency. Also the load and store address generators are included in what is called the Rapid Execution Engine since the autumn IDF. This is in contrast with earlier presentations which only mentioned the "double pumped" ALU. I had a conversation later on with chief architect Glenn Hinton who confirmed this. He agreed that it would have been possible to run the register file at the normal frequency with double the ports but that Intel had specifically chosen to run it at twice the normal frequency. This newly disclosed information means that 9 out of 20 pipeline stages contain double frequency components, much more then the 2 previously assumed. The fact that also the Address Generators run at double the frequency remains a bit puzzling since the 8 kByte L1 data cache runs at the normal frequency and won't accept anymore then 1 load and/or store address per cycle. Some more bits and pieces:
About the performance: Glenn Hinton expects that within three years most "power" applications will be re-written for the Pentium 4. Obvious if you think about it but still remarkable: The Spec2000 benchmarks run well on Willamette because the average Branch-miss prediction is only half of that of Spec95. The basic reason can be found in the much larger datasets. Loops will repeat longer in Spec2000 then in Spec95 and are therefor better predictable. That's about it. No really detailed disclosures
today. Glenn Hinton mentioned that it's Intel's policy to only disclose information
in a staged way when I asked him why he was so cautious in not letting me
know anymore then came out of Michael Upton's speech and that they may want
to keep some things secret all together. For instance the memory pre-fetching
techniques which seem to make such an important contribution to the
performance jump which the Coppermine made compared with it's direct (P6)
predecessors.
|
![]()
![]()