|
A new micro architecture is appearing in recent AMD patents. Here we have a first glance at this new processor core and discuss the possibility that it belongs to AMD's next years battleship: The double core SlegdeHammer. Interpreting patents is not straight forward. Many patents that are filled never make it into any product. The same may be the case for the processor core discussed here, however when more and more patents occur that show this core, the bigger the chance that it really belongs to a next generation product. The question then becomes which new product: one already on the current roadmap or one even further ahead in time. Sledgehammers double core The micro-architecture shown in the AMD patents have been stable the last few years and clearly belong to AMD's current flagship the Athlon. It has been publicly disclosed that the SledgeHammer will have two cores. Basically this could mean that there will be 2 processors on the die with a shared level 2 cache and memory interface. This is the approach followed in IBM's Power 4 server processor and provides two way multiprocessing on chip. Another approach which looks very promising is that of Compaqs EV8 or 21464 Simultaneous Multi Threading processor. It seems that this processor will double the processing resources of its current 21264. Revolutionary is the ability to do 4-way multithreading. It can run up to 4 threads at the same time with four program counters. Instructions from various thread travel down the pipeline and divide the processor resources. Alternatively a single thread may have the huge amount of processing resources for itself alone and run far faster than on any other uni-processor. That is: if and only if it's code contains a sufficient amount of ILP (Instruction Level Parallelism) That is often not the case and it would normally be not economical to put so much hardware into a uni-processor. SMT (Simultaneous Multi Threading) however provides the best of both worlds. It provides multiprocessing whereby the processors execution units are used with maximum efficiency but it can also operate as a shamelessly huge uni-processor. AMD's new micro-architecture seems to fit somewhere between these two approaches. Exactly what it can and can't do will probably become clearer when more and more patents arrive.
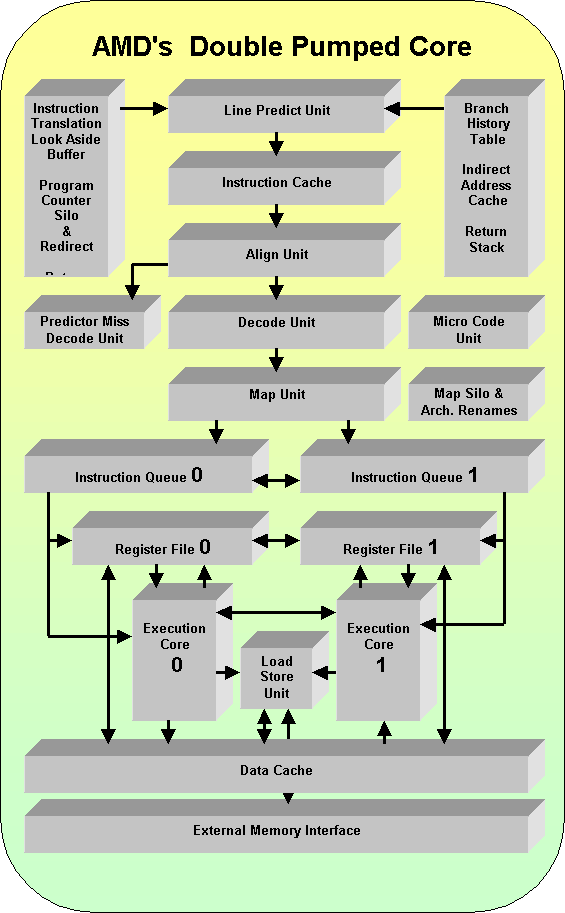
AMD's mister Patent The inventor named in the patents is David B.Witt. He has probably the most AMD patents (64) on his name after Tran M. Thang, another AMD master inventor with 100 patents. This might be a hint that the patents are indeed related to a major development within AMD. Reason enough to have a closer look. United line based Instruction decoding and renaming. The diagram shows that the two cores show the
same Instruction Cache/ Decoding system. New is that it handles Instruction-lines
instead of single instructions. A line can have up to 6 instructions
or up to 8 instruction operations. Some further study and following patents
may clarify what is exactly meant with this.
Two cores running in double pumped fashion. The pipeline splits into two halves after Register Renaming which is handled by the MAP unit together with the MAP Silo. The Instructions enter into Instruction Queues where the data dependencies are checked first the local dependencies and then against the other Queue. Instructions are scheduled. The renamed register files are accessed and data and instructions are dispatched to the two execution units. Both pipelines communicate whit each other. The clocks of the two pipelines are skewed by an 1/2 cycle. This means that data can be transferred from one pipeline to the other in 1/2 cycle instead of a full cycle. The results written into one instantiation of the register file are forwarded to the other one in the next 1/2 cycle. The number of 128 entries is mentioned as a typical size of a Renamed Register file. The Execution Units can likewise forward their results to each other within the 1/2 cycle. It is said that the Execution Units may typically contain a floating point adder plus multimedia unit, a floating point multiplier plus multimedia unit, two integer units, a branch unit, a load address generator, a store address generator and a store data unit. Other configurations are possible (edit: likely). Both Pipelines communicate with the Load/Store unit and the data cache. To be continued.... For so far a first glance at this new micro-architecture. Many questions remain: Will this really be a new AMD processor? And if so: Are the two cores shown the two cores mention in the Sledgehammer anouncements? Only time will tell... Probably little by little when new patents occure. The patents. US6122727:
symmetrical instructions queue for high clock frequency scheduling
|